Data book covers
This joint adventure with graphic design studio FBA. Is a tool that helps designers build visual artifacts to use in book covers design. The tool parses a text and exhibits its most frequents words, enabling the designer to choose which words they want to visualize by also choosing from more than a dozen of visualization models. The tool can map occurrences of selected words across the whole text. For instance, taking Tolstoy’s War and Peace, we can map Pierre Bezukhov, Natasha Rostov, Andrei Bolkonsky (in shades of blue) and Napoleon Bonaparte, Tsar Alexander I (in shades of red). As a result we have several visual artifacts from different visualization models. Each model has its own varying parameters that can create drastically different results (using dotted maps, temperature maps, circular and bar charts, texture based density maps, and even particles trajectories that are attracted to the occurrences of certain words).




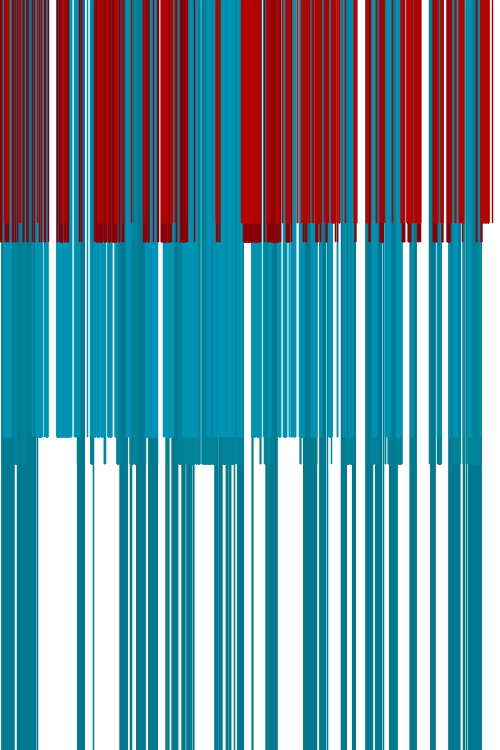



Taking these artifacts to the purpose of the tool (book covers design), I made some experiences based on Ana Boavida/FBA.’s designs for Minotauro collection of latin-american writers. For instance, I tend to select the characters of the book, coloring only the protagonists.



Business, marketing and law book covers using this tool, by designers Rita Marquito/FBA and Ana Boavida/FBA. Photographs by Daniel Santos/FBA.


Description of visualization models

A text in a book is typically organized in semantic aggregations (e.g. chapters, sections). Since the tool does not try to extract any semantic information by itself, I start by considering the text as one big line of words. The trick here is to pass this unidimensional nature to a 2D canvas. Histograms do it, but I prefer starting with maps. Therefore most of the models start by lying out the text through several horizontal lines, as if one page could represent the whole book. This way one can easily map in which portions of the text a certain character appears.

With this layout the position of each occurrence is determined. As seen on the left, I can represent each occurrence as a square. The color of the square is the attributed color to the corresponding word, while the size of is proportional to the total of occurrences in the text. Less occurring words are drawn above most frequent words in order to avoid occlusions.
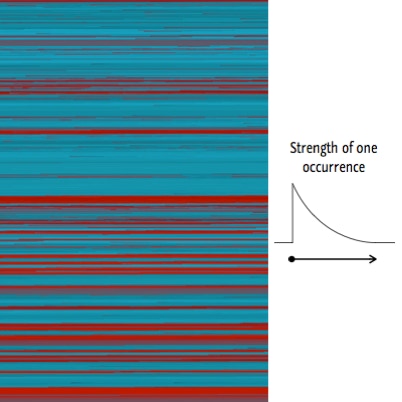
Instead of drawing squares over the occurrences, the colors of the pixels can be directly set weighting the proximity to word occurrences. The strategy adopted on the visualization at left only accounts for occurrences that are in the past, generating abrupt changes in color when unexpected occurrences are encountered while getting a washed out effect as the strength of each occurrence decreases while reading advances.
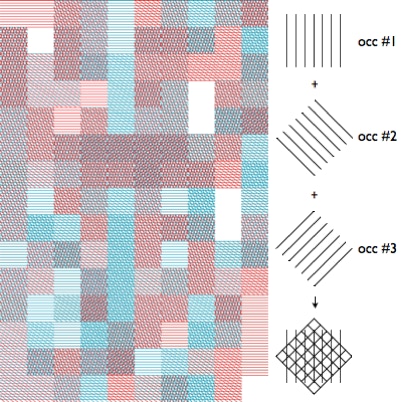
The text can also be divided in N portions of equal size. In each of these portions, if there are occurrences of a certain word, a corresponding pattern is drawn. The patterns for each selected word are dynamically generated through the rotation of a basic line-based pattern, assuring that each word has a unique pattern. In this way each portion of the text is represented trough an artifact that can be used do decipher the density of important occurrences and the similarity with other portions.
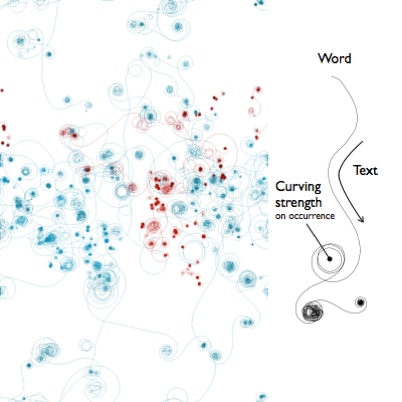
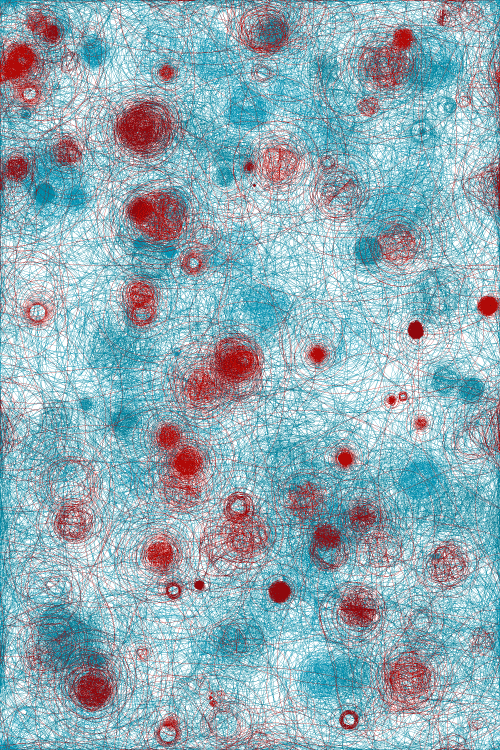
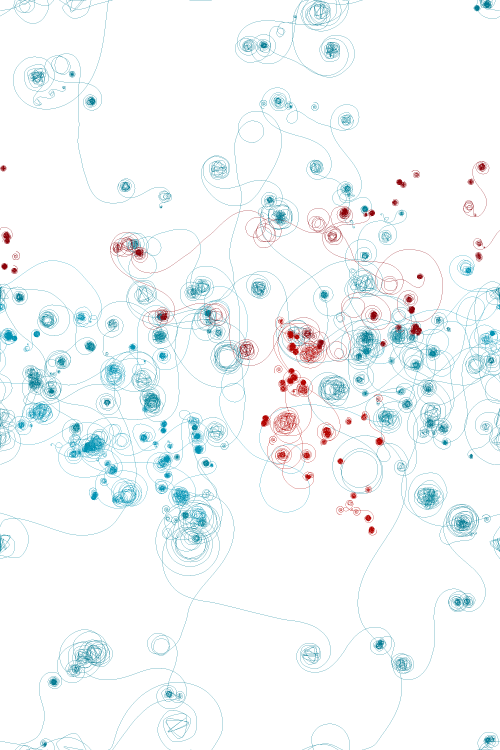
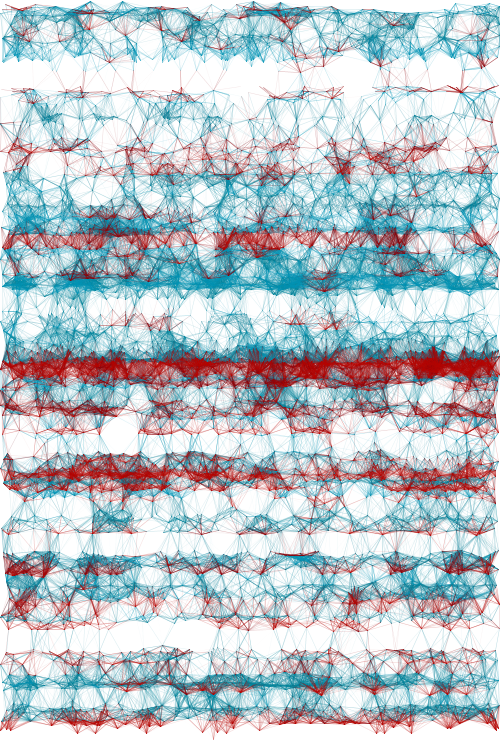
Perhaps the most adventurous visualization in the 2D realm is depicted at left. There is one trajectory for each selected word through its occurrences. The initial position is determined by the strategy previously described. The trajectory is then incremented as if the text was being advanced, curving as the reading position approximates a new occurrence. The qualitative dimension of the fur balls traduces an agglomeration of occurrences, so if an occurrence is isolated, the trajectory quickly converges to a point without much spinning. When the next occurrence is far ahead on the text, the trajectory will be rectilinear. Because I haven’t found the mixture of rects and curves of aesthetic interest, the rectilinear trajectories can be removed. When a trajectory spans canvas’ bounds it emerges in the opposite edge as like in a toroidal space. The intensity of the curvature and the looking ahead distance that aggregates the next occurrences are customizable, being able to generate a great variety of artifacts from the same visualization model.
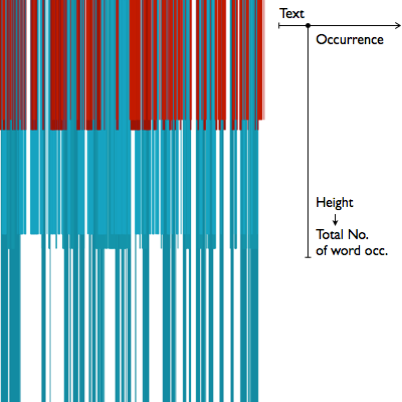
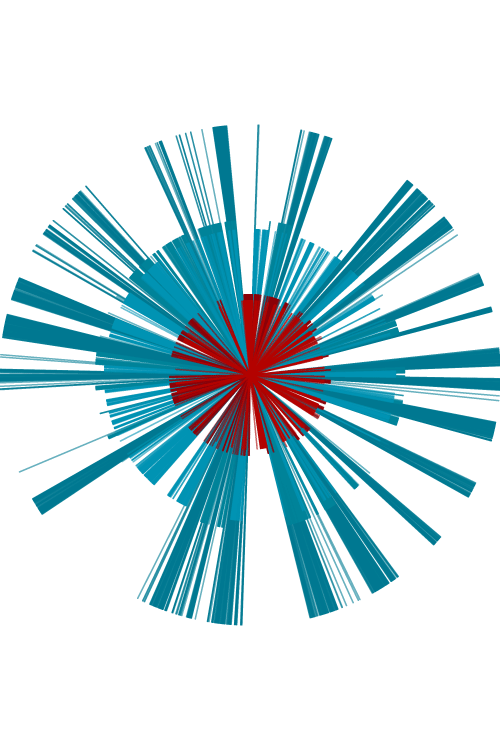
The next models aren’t based on the previously described positioning strategy. Instead they revolve in turn of the unidimensional nature of the text. At left, an atomic histogram of occurrences, where the height is the total number of occurrences of the corresponding word class.

The same histogram but with a circular base.